
📖 목차
💡 고민은 해시 맵이라는 추상화와 마주하게 된 날로부터
수천 개, 아니 수만 개의 많은 파일 속에서 같은 규칙으로 묶인 파일들을 Shift 드래그로 잡은 후 지정된 폴더에 던져본 경험은 한두번 있을 것이다. 같은 종류의 문서를 정리하거나, 동일한 음악의 아티스트를 묶거나, 앨범의 개별 곡을 정리하거나 하는 등 다양한 방식으로 한두번쯤 경험해볼법 한 워크 플로우(work flow)일 것이다.
그래서 나는 이러한 반복되는 작업을 추상화된 코드로서 작업을 간단하게 만드는 파이썬 코드를 작성했었다. 그런데 위에서 설명한 작업 흐름을 코딩하였을 때, 메모리 구조를 떠올리면서 각 데이터가 저장된 방을 하나씩 노크해가며 ‘당신이 여기에 있는 내용과 일치하나요?’라는 원시적인 방법으로 O(n²) 코드를 작성하여 처리하도록 했다.1
당연히, 코드는 문제없이 잘 돌아갔고 내가 원하는대로 작업은 됐다. 그런데 뭔가 이상한 점을 느꼈는데, 작업이 처리되는 과정이 생각보다 많이 느린 것을 발견했다. 기초적인 실수 중 하나인 다중 for 문이 문제라는 걸 직감하고, 어떻게 이걸 처리해야할까 고민하기 시작했다.
그리고 뒤늦게 파이썬에서 해시 맵(Hash Map)을 아주 쉽게 사용할 수 있는 딕셔너리가 있다는걸 깨달았다!
🪄 당연히 그런 경우에는 O(1)인 해시 맵을 사용해야지!
그렇다. 당연히 이러한 문제 해결을 위해 해시 맵을 사용하여 처리하는 건 막 입문한 개발자들이 놓치기 쉬운 부분에 속한다. 하지만 가볍게 쓱 알고 넘어가는 것 보다 좀 더 깊게 생각해보자.
왜 해시 맵은 어떻게 O(1)이라는 속도에 도달 할 수 있을까? 당연히 여기에대한 답으로서는 다들 ‘키-값 쌍으로 이루어진 데이터로서, 메모리 주소를 바로 찾을 수 있는 해시 함수의 역할 때문에 그런거죠. 기본 아닌가요?‘라고 할 것 이다. 그리고 그에 대한 이해를 쉽게 설명하기 위해 단순히 추상화된 메모리 구조(배열) 형태의 그림을 가져와 설명 할 것이다.
자, 다시 한번 좀 더 깊게 생각해보자. 그 추상화 된 메모리 구조는 어디로부터 나온 것인지 생각해보자.
📌 실제 CPU 메모리 컨트롤러와 메모리 물리적 구조 (without. code)
탑 다운(Top down) 방식으로 내려오는 이 사고과정은 우리를 CPU의 메모리 컨트롤러와 RAM이라는 구조로 발걸음을 옮기게 만든다.
혹자는 ‘아니 추상화된 메모리 구조가 RAM이죠. 당연한거 아니에요?‘ 라고 할 수 있다.
하지만, 그 대답은 어떻게 해시 맵 구조가 현실 세계. 즉, 실제 CPU와 RAM 간의 작업과정을 자세하게 설명하지 못한다.
파이썬의 딕셔너리와 같이, Java의 java.util에 포함된 HashMap 구조, C++에서 해시로 사용 할 수 있는 std:unordered_map, C#의 딕셔너리인 Dictionary <TKey,TValue>, Rust의 std::collections::HashMap 등의 다양한 언어에서 사용되는 해시 맵 구조는 실제 세계에서 해시 함수를 통해 CPU가 RAM에 접근하여 키(Key)를 들고 해당되는 메모리 주소를 찾아서 값(Value)을 반환하는 것이다.
여기까지보면, 그저 단순하게 기존에 통상적으로 널리 알려진 개념하고 동일하게 말한거라고 생각할 수 있을 것이다.
하지만, 지금부터 본격적으로 이야기하는 해시 함수가 해시 맵을 처리하는 실제 물리세계의 구조를 살펴보면 본 글의 의도를 알 수 있게 될 것이다.
🔎 범용적으로 사용되는 데스크탑(PC)의 구조를 직접 살펴보자!
우리가 컴퓨터를 조립할때, 케이스 내부에 메인보드가 장착되어 있고 거기에 CPU를 꼽고, 메모리도 꼽고, 디스크도 꼽는 등의 방식으로 진행할 것이다. 여기서 CPU와 RAM 연결되어 있는 부분을 자세히 보자.

CPU와 RAM 사이에 그어진 회로를 보면 여러개의 선이 CPU와 RAM(DIMM) 사이를 연결하고 있을 것이다.2
자, 그러면 CPU와 RAM 사이에 회로가 그려져있는건 인지했다. 하지만, 어떻게 CPU는 RAM과 연결되어 처리가 되는 걸까?
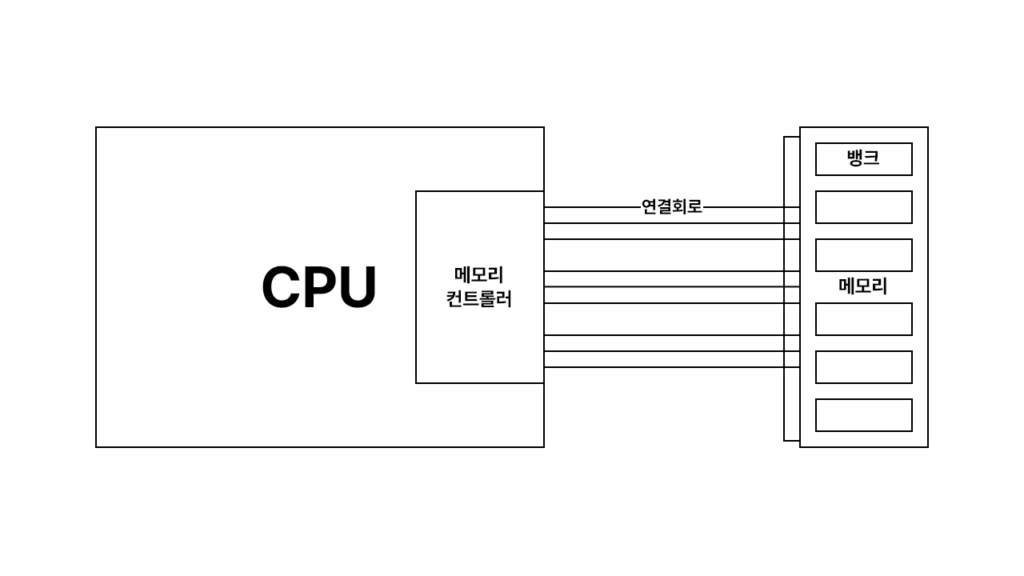
이는 CPU의 메모리 컨트롤러의 존재를 생각해보면 된다.3 CPU 내부에 존재하는 메모리 컨트롤러는 아까 우리가 보았던 그 회로를 통해 RAM에 연결되고, DIMM(dual in-line memory module) 소켓에 꼽혀있는 RAM의 수많은 핀을 통해 고속으로 메모리 뱅크에 접근하여 데이터를 읽고 쓰게 된다.
바로 이게 우리가 프로그래밍에 사용되는 메모리 주소 구조로서, 실제 물리 세계를 추상화한 형태이다. 그 일차원 배열로 저장되는 메모리 구조의 그림이 바로 이와 같은 실제 CPU와 RAM 사이를 축약한 것이라고 생각하면 이해하기 쉬울 것이다.4
🤝 포인터와 메모리 구조 그리고 해시 맵 구조와의 상관관계
다음으로 발걸음을 옮겨 C언어를 생각해보자. C언어에서 많은 학부생과 개발자들을 다중 포인터로 머리를 부여잡게 만들었던 그 포인터의 개념을 떠올려보자. 포인터 변수는 어떤 변수인가? 메모리 주소를 가리키는 변수이다. 어라? 슬슬 무언가 보이기 시작할 것이다.
그렇다. 위에서 설명한 각 언어의 해시 맵은 이러한 포인터 개념을 기반으로하는 자료구조이다.
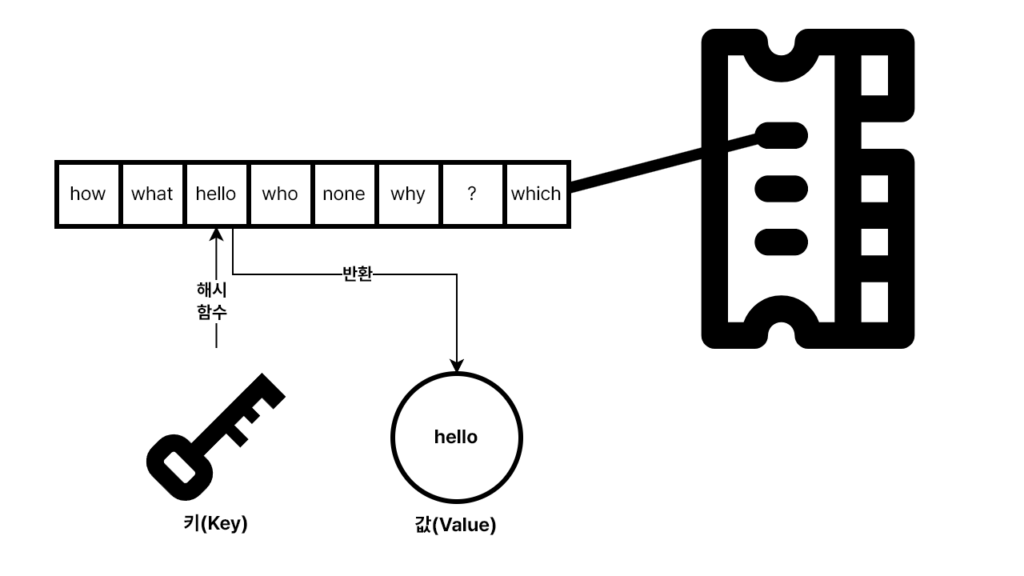
해시 맵을 작동시키는 해시 함수는 실제 물리적인 구조인 메모리 주소를 기억하고 있다가 키(Key)를 받았을 때, 빠르게 해당되는 메모리 주소를 찾아서 키로 문을 열어 값이라는 데이터를 가져오는 것이다. 이 사고과정을 다시 연결하여, CPU의 메모리 컨트롤러에서 RAM과 연결된 회로를 타고 RAM에 저장된 데이터 주소를 들고 정확하게 데이터가 있는 지점을 방문하여 데이터를 가져오는 것이다. 그래서 순차적으로 메모리 주소를 스캔하는 원시적인 방법이 필요없이, 그저 주소만 들고 물건을 배달하는 우체부의 모습을 떠올리는 결론에 도달 할 것이다.
우체부가 굳이 배달하지도 않을 집을 일일이 하나씩 방문할 필요없이, 배달해야 할 주소 목록만 가지고 방문하는게 당연히 더 효율적이니까! 그리고 이것이 O(n)과 O(1)의 차이를 판가름 하는 중요한 요소이다. 더이상 설명이 필요없을 정도로 쉽게 말이다.
처음 파이썬이라는 딕셔너리라는 마법이라고 한, 진실된 마법 구조는 이와 같은 개념을 기본으로 하기 때문이다. 그래서, 우리는 O(n) 같은 방법으로 노크를 할 필요없이 O(1)로 빠르게 처리할 수 있는 것이다.
⚠️ 하지만 해시충돌(Hash Collision)이 발생한다면?
어디까지나 해시 맵의 O(n)이라는 속도는 평균이다. 해시충돌이 발생한다면 이러한 빠른 속도를 보여주는게 아니고 생각보다 많이 느려질 수 있는 점을 기억해야한다. 해시충돌에 관한 내용을 더 설명하기에는 글 내용이 길어질 수 있어 다음에 보충 설명하는 글을 작성하도록 하겠다.
📒 결론: 편리함 뒤에 숨겨진 원리
사실 이 글을 작성하게 된 이유는 서론에서 언급했던과 동일하게 그저 아주 기본적인 이슈인, 다중 for 문을 풀어 속도를 개선하기 위한 점에서 시작되었다. 하지만, 이 문제를 해결하면서 마주하게 된 파이썬과 같은 고수준(High-Level) 언어의 추상화된 메서드들은 편리하기도 하지만, 우리가 실제 작동되는 물리세계의 모습을 안개로 가려 외면하게 만드는 요소일 수 있다.
물론, 추상화는 이러한 복잡한 개념을 생략하고 간단하고 편리하게 쓰기 위한 도구이다. 그리고 모든 개발자들이 이러한 물리세계를 굳이 알 필요 없지 않냐는 반박을 쉽게 부정하지 못할 것이다.
하지만, 이와 같은 과정과 결론은 개발에 입문하는 개발자로서 단순히 ‘자료구조’의 문제를 논리적인 개념으로만 인식할 것이 아닌, 물리적인 진실 또한 왜 엔지니어에게 있어 중요한 메시지를 던지는 매개체인지 생각하게 만들어 준다.
- 물론, O(n²)이 된 이유는 파일 중복처리를 위한 부분을 구현하는 부분이 포함된 것도 이유긴 했다. ↩︎
- 보통 듀얼채널 메모리 구조인 회로를 보게 될 것이다. 본인이 서버나 워크스테이션 보드를 보유중이라면 쿼드채널 이상의 회로를 보게 될 것이다. ↩︎
- 물론 너무 오래된 컴퓨터로 보고 있다면(특히, 펜티엄4, 코어 2듀오 이전 시절), CPU 대신 노스 브릿지라고 불리는 컨트롤러가 대신 메모리 컨트롤러 역할을 하고 있다. 메모리 컨트롤러가 CPU에 내장된건 인텔 기준 코어 i시리즈(네할렘)이후 쯤이다. ↩︎
- 당연히, 이러한 듀얼채널, 쿼드채널 구성의 RAM을 CPU에서 인식하여 OS상에서 보여지는 것은 이러한 고도화된 추상화 덕분이다. 이러한 추상화가 없었다면 개발자들 모두 실제 물리 메모리를 컨트롤하며 듀얼채널 이상의 병렬화된 구조를 신경쓰느라 애먹었을 것이다. 하지만, CPU와 OS가 이를 처리하기 때문에 우리 모두 쉽게 메모리를 사용할 수 있는 것이다. ↩︎